Le Consortium Couperin a publié récemment les résultats d’une enquête sur les « Pratiques de publication et d’accès ouvert des chercheurs français« , qui se démarque par son ampleur (plus de 11 000 réponses de chercheurs, soit 10% de la communauté scientifique française) et l’étendue des questions abordées. Beaucoup de points mériteraient d’être commentés, mais je voudrais me concentrer sur un seul aspect qui m’a particulièrement frappé.

On peut en effet lire cette phrase dans la synthèse effectuée par Couperin à partir des résultats :
Les chercheurs sont globalement favorables à l’accès ouvert et en comprennent l’enjeu majeur : la diffusion des résultats de la science de façon libre et gratuite. Néanmoins, cet objectif doit pour eux être réalisé sans effort, de manière simple, lisible et sans financement direct des laboratoires, le tout en ne bousculant pas trop le paysage des revues traditionnelles de leur discipline auxquelles ils sont attachés.
J’ai souligné les mots « sans effort », car ils me paraissent intéressants à relever. En gros, les chercheurs sont favorables au Libre Accès, à condition qu’il n’entraîne pour eux aucun surcroît de travail à effectuer. Si, d’après l’enquête, la méconnaissance des questions juridiques liées au Libre Accès reste le premier obstacle au dépôt en archives ouvertes, on trouve en seconde position des arguments du type : « Je n’ai pas le temps » ou « le dépôt est trop laborieux ». L’archive ouverte HAL attire encore souvent ce genre de critiques, et ce alors même que la procédure de dépôt a été grandement simplifiée ces dernières années (ajout de fichiers en glissé-déposé, diminution des champs obligatoires, possibilité de récupérer automatiquement les métadonnées via un DOI, etc.).
En réalité, les positions exprimées par les chercheurs à propos des archives ouvertes sont assez paradoxales. Une majorité d’entre eux trouvent en effet que le dépôt est « rapide » et « simple » (voir ci-dessous), ce qui paraît contradictoire avec l’argument du manque de temps ou des interfaces trop complexes.
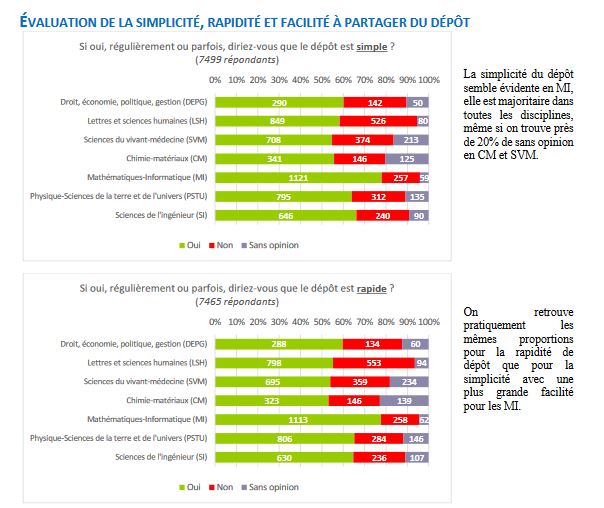
L’enquête permettait aux chercheurs de laisser des commentaires libres, qui montrent que le vrai problème se situe sans doute ailleurs que dans l’ergonomie des plateformes. Une partie des chercheurs tendent en effet à considérer que ces tâches de dépôt – même simples et rapides à effectuer – ne correspondent pas à l’image qu’ils se font de leur travail :
« Ce n’est pas mon travail, je suis déjà très pris par des charges administratives je ne vais pas en plus faire ce type de tâches. »
« Ceci n’est pas du ressort d’un enseignant-chercheur dont on demande de plus en plus de tâches administratives ou « transversales » en plus de son travail d’enseignement et de recherche. Donc, j’estime que le dépôt sous HAL doit être assuré par des personnels archivistes dont c’est effectivement le métier ! Tant que les moyens ne seront pas mis pour ouvrir des postes à ces personnels, je refuserai de faire ce travail sous HAL. »
« Je dépose les références minimales, pour l’évaluation HCERS mais pas les articles.De mon point de vue, c’est l’institution qui doit se charger de la mise en ligne des notices et des articles (après obtention accord de l’auteur) et comme elle ne s’en charge pas… Je fais donc le minimum. »
Dans ce billet, je voudrais essayer d’éclairer ces positions ambivalentes en utilisant la notion de Digital Labor (travail numérique). Pour ce faire, je ne vais pas me référer à l’acception la plus courante du terme « Digital Labor », telle que l’utilise notamment Antonio Casilli dans ses travaux sur les plateformes numériques et l’intelligence artificielle. Je vais me tourner vers une conception plus large, que j’ai découverte dans l’ouvrage (remarquable) du sociologue Jérôme Denis : « Le travail invisible des données. Éléments pour une sociologie des infrastructures scripturales« .

Omniprésence et invisibilité du travail des données
Pour Jérôme Denis, le « travail des données » n’est pas un phénomène récent et il dépasse très largement les situations où les internautes sont « mis au travail » à leur insu par des plateformes comme Facebook ou Amazon. Il s’agit plutôt d’une caractéristique générale de toutes les organisations – publiques comme privées – qui ont besoin de produire et de faire circuler de l’information pour fonctionner. Sans cette capacité à organiser des flux de données standardisées, ni les entreprises, ni les administrations ne pourraient exister, dès lors qu’elles atteignent une certaine taille et se bureaucratisent. Jérôme Denis ajoute que, bien que ce « travail des données » soit absolument vital pour ces organisations, il a pourtant constamment été minimisé, dévalorisé et même invisibilisé. En témoigne la manière dont ces tâches ont été déléguées à des personnels généralement considérés comme subalternes – les secrétaires, par exemple – et il n’est pas anodin que les professions liées à l’information furent traditionnellement – et sont en grande partie toujours – exercées majoritairement par des femmes (c’est vrai des secrétaires, mais aussi des bibliothécaires ou des documentalistes).
Paradoxalement là encore, l’informatisation des organisations est venue aggraver ce phénomène de dépréciation et d’invisibilisation. Le déploiement des ordinateurs en réseau s’est accompagné d’une croyance en vertu de laquelle l’information pourrait se propager avec la facilité et la rapidité du courant électrique, comme des impulsions le long d’un système nerveux. Ce mythe est lié au fantasme de la « dématérialisation » qui, en libérant (soit-disant) l’information de ses supports physiques, lui permettrait de circuler comme un fluide parfait. Pourtant, et c’est une chose que le livre de Jérôme Denis montre remarquablement bien, le numérique ne supprime pas en réalité le « travail des données ». Bien au contraire, l’information reste largement dépendante de supports matériels (claviers, écrans, etc.) et la numérisation tend même à intensifier et à complexifier le travail informationnel (songeons par exemple au temps invraisemblable que nous passons à gérer nos boîtes mail professionnelles et à la pénibilité que cela engendre).
Un des avantages de cette conception large du « travail des données » est qu’elle permet d’embrasser et d’éclairer tout un ensemble de situations auxquelles nous sommes quotidiennement confrontés. Pour illustrer son propos, Jérôme Denis prend notamment un exemple tiré de son expérience personnelle que j’ai trouvé particulièrement frappant. Il raconte en effet comment, après la mort de son père, il a été obligé d’effectuer avec sa famille pendant des mois de laborieuses démarches pour « pousser » l’information du décès vers de nombreuses organisations : administrations en tout genre, banques, assurances, boutiques en ligne, fournisseurs d’accès Internet, etc. Rien ne paraît pourtant plus élémentaire que l’annonce de la disparition d’une personne (vie/mort ; 0/1) et on pourrait penser à l’heure du numérique qu’une telle mise à jour des systèmes d’information est relativement simple à effectuer. Mais il n’en est rien et malgré l’interconnexion croissante des bases de données, une part importante du travail doit encore être effectué « à la main » par l’administré/client, en saisissant l’information dans des interfaces et en remplissant des formulaires.
Il existe donc une sorte « viscosité » de l’information que le numérique n’a pas fait disparaître et ne supprimera sans doute jamais complètement, sachant qu’il engendre sa propre part de « frictions » dans la production et la circulation des données.
Quelle perception du « travail des données » chez les chercheurs ?
La question n’est donc pas tant de chercher à faire disparaître le « travail des données » que de savoir quel statut et quelle reconnaissance on lui donne. La perception de la « pénibilité » de ce travail varie en outre grandement d’un contexte à un autre, non pas tellement en fonction de caractéristiques objectives, mais plutôt par rapport à la représentation que les individus s’en font.
Si l’on revient à la question de l’Open Access, j’ai toujours trouvé qu’il existait une forme de dialogue de sourds entre chercheurs et bibliothécaires/documentalistes à propos du dépôt des publications en archives ouvertes. Pour ces derniers, qui sont des professionnels de l’information, le dépôt des publications paraît quelque chose de simple, en partie parce que le travail des données est inhérent à leur métier et n’est pas déprécié symboliquement à leurs yeux. A l’inverse pour la majorité des chercheurs, un tel travail – même léger – suscitera un rejet mécanique, parce qu’il fait apparaître ce qui devrait rester invisible. Ce qui est intéressant, c’est que les mêmes chercheurs qui refusent d’effectuer les tâches de dépôt en archives ouvertes réalisent pourtant des opérations assez similaires dans leur pratique des réseaux sociaux académiques (type Researchgate ou Academia). C’est précisément le coup de génie (maléfique !) de ces plateformes d’avoir réussi à « mettre au travail » les chercheurs sans lever le voile d’invisibilité qui rend ce travail des données indolore (et pour le coup, on rejoint ici la thématique classique du Digital Labor comme exploitation des utilisateurs).

S’agissant des chercheurs, les choses sont encore compliquées par le fait qu’ils entretiennent traditionnellement un rapport ambigu avec la question des données. S’appuyant sur les apports des science studies, Jérôme Denis souligne le fait que ce sont les articles de recherche qui sont considérés depuis des siècles par les scientifiques comme les objets chargés de la plus haute valeur symbolique. Il en est ainsi car les articles, une fois mis en forme à l’issue du processus éditorial, deviennent des « mobiles immuables », c’est-à-dire des objets doués de la capacité de circuler, mais tout en gardant une forme fixe. Ils assurent ainsi la communication entre pairs des résultats de la recherche et c’est à partir d’eux quasi exclusivement que s’effectue l’évaluation de la recherche et des chercheurs. Dans un tel contexte, il est logique que le travail d’écriture des articles – celui qui assure justement cette stabilisation de la forme – soit considéré comme la partie la plus noble du travail des chercheurs, tandis que, par contraste, ce qui touche aux données – réputées instables, informes et volatiles – est rejeté dans l’ombre. A la mise en lumière des articles s’oppose la « boîte noire » du laboratoire, où le travail sur les données reste considéré comme quelque chose d’obscur, et même un peu « sale », dont traditionnellement on ne parle pas.
Certes, les choses sont en train de changer, car les données de recherche, à la faveur des politiques de Science Ouverte, gagnent peu à peu leurs lettres de noblesse, en tant qu’objets possédant intrinsèquement une valeur et méritant d’être exposés au grand jour. Mais nul doute qu’il faudra du temps pour que les représentations évoluent et l’enquête de Couperin montre d’ailleurs que si les chercheurs sont aujourd’hui globalement favorables à l’Open Access aux publications, ils restent plus réticents en ce qui concerne le partage des données.
Du coup, le travail des données est doublement dévalorisé au sein des populations de chercheurs. Il subit d’abord la dépréciation générale qui le frappe au sein des organisations modernes, mais cet effet est redoublé par la hiérarchie traditionnelle établie par les chercheurs entre travail rédactionnel et travail informationnel. Or le dépôt en archives ouvertes est précisément ce moment où le travail des données qu’on voudrait pouvoir oublier resurgit. « Cachez ces métadonnées que je ne saurais voir », alors qu’elles sont indispensables pour contextualiser les documents archivés et leur donner du sens…
Changer le statut du travail des données pour promouvoir le Libre Accès
Établir un lien entre Open Access et Digital Labor (au sens large de « travail des données ») est à mon sens important pour mieux comprendre le rapport conflictuel que les chercheurs entretiennent avec les archives ouvertes et leur demande que le Libre Accès s’effectue « sans effort ». Il me semble que cela pourrait au moins s’avérer utile pour identifier quelques « fausses bonnes idées » :
- Croire qu’en améliorant techniquement les interfaces des archives ouvertes, on pourra un jour supprimer complètement le « travail des données » lié au dépôt des publications et le rendre indolore. On trouve aujourd’hui des discours qui nous promettent la mise en place d’interfaces « seamless » (i.e. « sans couture ») qui permettraient une expérience utilisateur parfaitement fluide. On peut certes faire des progrès en matière d’ergonomie, mais il restera toujours à mon sens une part de « travail du clic » à effectuer et tant qu’il sera frappé d’une dépréciation symbolique, il suscitera une forme de rejet par les chercheurs.
- Proposer aux chercheurs d’effectuer l’intégralité de ce travail des données à leur place. C’est certes une demande que certains formulent (« ce n’est pas mon métier ; que l’on embauche des documentalistes pour le faire à ma place »). Mais outre qu’il paraît improbable de recruter un nombre suffisant de personnels d’appui pour effectuer l’intégralité de ce travail, cela ne ferait que participer encore à l’invisibilisation du travail des données et à sa dévalorisation. Les bibliothécaires qui s’engagent dans cette voie se livrent à mon sens à un calcul à court terme qui risque de s’avérer préjudiciable à long terme pour tout le monde.
- Faire effectuer ce travail des données par les éditeurs. C’est à mon sens la pire des solutions possibles et le dernier accord Couperin-Elsevier a bien montré les dangers que pouvait comporter l’idée de « sous-traiter » l’alimentation des archives ouvertes aux éditeurs. C’est aussi parce qu’il garantit justement le plein contrôle des interfaces et des données que le principe d’une alimentation des archives ouvertes par les chercheurs eux-mêmes reste absolument crucial.
Au final pour développer la pratique de l’Open Access, c’est le statut de ce « travail des données » qu’il faudrait faire évoluer au sein des communautés scientifiques pour qu’il regagne ses lettres de noblesses, lui donner la visibilité qu’il mérite et le faire apparaître comme partie intégrante de l’activité de publication. La question ne concerne d’ailleurs pas que le Libre Accès aux publications, mais aussi les données de la recherche qui gagnent peu à peu en importance. Néanmoins, cette dernière thématique étant en train de devenir « à la mode », elle va sans doute faire l’objet d’une revalorisation symbolique, tandis que l’on peut craindre que le travail informationnel à effectuer pour alimenter les archives ouvertes reste encore longtemps frappé d’indignité.
Dans l’enquête Couperin, on voit bien par exemple que les communautés de mathématiciens et d’informaticiens sont celles qui ont le plus recours aux archives ouvertes et ce sont justement aussi celles qui ont le moins « externalisé » le travail informationnel, puisque les chercheurs dans ces disciplines effectuent eux-mêmes une large partie du travail de mise en forme des publications (avec LaTeX) et de dépôt des préprints sur ArXiv.


Billet très juste, j’ajoute simplement trois bémols.
1/ Le succès de RG et d’Academia est dû à l’absence de demande de metadonnées, donc il n’y a pas ou très peu de « travail de données » à effectuer pour leurs utilisateur en ce qui concerne leurs papiers « déposés » ou « aspirés ». En revanche, parler d’eaux et de leurs CV, compter leurs citation n’est pas du travail :-)
2/ Le « travail des données » est d’intensité très variable suivant les communautés disciplinaires : les maths, l’info et les SHS ont en moyenne un nombre d’auteurs très faible comparé à la biologie et encore plus à certaines branches de la physique.
3/ A l’exception des affiliations, ce sont des données très standards au point que la récupération du DOI permet de les remplir en grande partie. Et comme HAL a renoncé à l’exigence d’affiliation hors du déposant, il n’y a pratiquement plus rien à faire si la publication a un DOI. Cela n’empêchera pas nombre de chercheurs de considérer que c’est encore trop, puisqu’ils ne voient pas l’intérêt même du dépôt.
Merci pour votre lecture et votre commentaire.
Je réponds sur les trois points :
1) En effet, ResearchGate et Academia font l’impasse sur le travail de production des métadonnées sur les publications. Ce n’est tout simplement pas ce qui les intéressent (j’imagine que pour leurs recommandations, ils doivent simplement directement fouiller dans le plein texte des publications). En tant que réseaux sociaux, ce sont les données personnelles des chercheurs qu’ils convoitent, ainsi que le réseaux des relations que les chercheurs entretiennent entre eux. Et pour le coup, les chercheurs sont bien mis au travail par ces plateformes pour produire et entretenir ces données, comme nous le sommes tous sur Facebook, Twitter et LinkedIn. Cela relève plus directement de la problématique du Digital Labor plutôt que de celle du « travail des données » que j’utilise ici.
2) Oui, vous avez tout à fait raison. Un des facteurs qui compliquent le dépôt en archives ouvertes est le nombre de co-signataires des publications qui varient selon les disciplines. Ce n’est d’ailleurs peut-être pas un hasard si en biologie et dans certains secteurs de la physique, les modèles de publication en Open Access avec paiement de frais (APC) sont plus largement développés, car cela revient aussi à transférer le « travail des données » sur les éditeurs.
3) Et oui encore, l’utilisation du DOI pour récupérer automatiquement les métadonnées diminue drastiquement le travail des données lié à un dépôt en archives ouvertes. Mais j’ai tendance à penser que tant qu’il restera un clic, ce sera encore trop, si la perception du travail des données ne change pas. D’ailleurs, plus de 80% des chercheurs qui ont répondu à l’enquête déclarent comprendre l’intérêt du Libre Accès et soutenir la démarche, mais on reste encore à beaucoup moins de 80% de dépôts. Même pour les chercheurs volontaires, la « friction » incompressible reste un réel obstacle.
Merci pour cet excellent billet qui met des mots sur ce que je perçois depuis longtemps du comportement des chercheurs, et que l’enquête avait confirmé. Je suis d’accord sur les dangers que les bibliothèques prennent en proposant aux chercheurs de faire ce travail à leur place. Pour moi le dépôt en archive ouverte doit devenir pour les chercheurs la dernière étape du processus de publication, c’est en ce sens qu’on doit essayer de les convaincre, en tout cas dans les disciplines où la pratique n’est pas naturelle.
Merci pour ton commentaire et je me réjouis que nous soyons d’accord concernant le rôle des bibliothèques.
J’en profite pour te féliciter, ainsi que les autres personnes qui ont travaillé avec toi, car cette enquête est vraiment extrêmement intéressante et je pense que cela restera comme un document de référence pour longtemps. Il y a énormément de choses à en tirer et merci également pour la synthèse qui rend les résultats plus facilement appropriables.
Merci pour ce billet intéressant au sujet des relations possibles qu’entretiennent les chercheurs avec différents types de données.
Tout d’abord j’insisterais sur la différenciation des types de données : les données utilisées lors d’une recherche diffèrent des données dont tu fais mention lorsqu’il faut saisir quelques champs pour téléverser son article ou rapport sur une archive ouverte ou un dépôt privé.
Comme tu l’as dit il y a une contradiction sur le travail fourni par les chercheurs pour mettre a jour des données et métadonnées sur leur compte Academia ou Research Gate. Ce n’est pas une contradiction entre leur pratique d’une part vis à vis d’une archive ouverte et d’autre part d’un dépôt privé type Academia mais une différence au niveau des intentions et buts visés. Ces deux sites sont tout d’abord plus qu’un dépôt mais ils sont aussi réseau social contrairement à l’archive ouverte HAL. Les chercheurs aiment probablement aussi naviguer entre les réseaux pour découvrir d’autres publications. Deuxièmement, ces réseaux sont considérés comme plus vus, consultés. On se trouve dans la même recherche de visibilité qu’un réseau social. Ainsi le labeur sur les données en vaut la chandelle pour les chercheurs. Comme tu le soulignes très justement un travail sur les données est considéré quelques fois comme une tache subalterne.
C’est pour la même raison que des chercheurs ne vont soumettre des articles que dans certaines revues qui sont dans les meilleures places selon différents classements internationaux.
Donc le chercheur « se met au travail » que elle ou il s’estime espérer un bénéfice pour sa carrière. En somme je pense que la pénibilité évoquée serait un prétexte.
Sur les données de recherche elle-même, je dirais qu’elles sont rarement déposées en intégralité pour des questions d’accessibilités, d’interopérabilités d’une part. D’autre part, les données de recherche sont parfois aussi considérées comme une mine d’or potentielle pour de possibles articles ultérieurs. Enfin, elles constituent parfois la partie la plus longue et difficile partie du travail de chercheur. Par conséquent, il ou elle ne souhaite pas forcément les partager aussi facilement.
Je ne crois pas que la pénibilité soit uniquement un prétexte. Je pense que celle-ci est en réalité purement subjective et qu’elle dépend de la représentation que les acteurs se font du travail sur les données.
J’ai eu l’idée de faire cet article, car si je prends mon cas personnel, déposer un article dans HAL est quelque chose qui ne provoque chez moi absolument aucune pénibilité, même pour des dépôts un peu complexes. Pourtant, en général dans la vie, je déteste effectuer des démarches en ligne et je suis même capable de me mettre dans des situations parfois compliquées juste pour éviter de me confronter à des interfaces.
Je pense que cela tient au fait que je suis bibliothécaire de formation et que je vois le fait de produire des métadonnées comme quelque chose de positif. Du coup, cela supprime la pénibilité liée à ce « travail du clic ».
Et il me semble que c’est la même chose pour les chercheurs. Le travail des données est quelque chose de dévalorisé chez la plupart d’entre eux (cela varie néanmoins grandement selon les communautés et les disciplines). Et sur les réseaux sociaux académiques, ce « travail » n’apparaît tout simplement pas comme tel, de la même manière que les gens n’ont pas la sensation d’être au travail lorsqu’ils utilisent Facebook et Twitter (alors même qu’ils le sont).
Le dépôt dans l’archive ouverte HAL depuis un DOI ou un PDF existe depuis une 10aine d’année maintenant. Nous n’avons pas constaté pour autant une explosion des dépôts en texte intégral. Le « succès » des bases Academia ou Research Gate ne réside t il pas selon vous soit dans l’aspect international soit dans l’anticipation/la récupération tout azimut des dépôts voir les deux ?
J’aurais tendance à dire que le succès d’Academia ou Research Gate vient du fait qu’ils sont centrés sur les profils de chercheurs et non sur les documents, ce qui est le tropisme des archives. Cela donne aux chercheurs le sentiment de travailler pour eux et non pour les documents…
Et cela rentre plus facilement en résonance avec « l’égonomie » de la recherche.
Ceci étant dit, les chiffres ont tendance montrer qu’en termes de trafic et de visibilité, HAL est tout à fait capable de faire jeu égal avec les réseaux sociaux académiques.
Oui Calimaq, il ne fait aucun doute que c’est la subjectivité de chaque acteur qui participe la l’élaboration de son jugement. Je n’ai pas lu l’étude qui est le point de départ de ton billet. Cependant je me permets cette hypothèse par rapport à mon expérience de chercheur au Canada. L’hypothèse étant que cette subjectivité se construit par rapport au but visé par ce travail sur les données. J’utilise le mot prétexte car il me semble que cet argument cache une raison peut être moins facilement avouable qui est celui d’une logique d’autopromotion via les réseaux sociaux spécialisés. À cause de mise en concurrence internationales des chercheurs, les publications diffusées par les plateformes d’éditeurs ne suffisent pas ; les chercheurs utilisent d’autres moyens pour publiciser et augmenter la visibilité de leur travaux par d’autres moyens. Par exemple, dès qu’un collègue chercheur met en ligne un nouveau papier sur un réseau social académique je suis au courant directement par ma boite email de cette nouvelle publication tandis que s’il le ferait sur HAL l’information n’irait pas vers moi directement. Ce peut être un exemple des différences de buts visés pour un même travail de données. Il serait intéressant de voir si l’étude à questionner cette différence de représentation qu’auraient les chercheurs sur l’efficacité en terme de publicité et diffusion entre une archive de type HAL et celle d’un réseau social académique. C’est une autre question qui pourrait en partie infirmer ou pas mon hypothèse.
« Et sur les réseaux sociaux académiques, ce « travail » n’apparaît tout simplement pas comme tel, de la même manière que les gens n’ont pas la sensation d’être au travail lorsqu’ils utilisent Facebook et Twitter (alors même qu’ils le sont). »
Exactement! Une même tâche n’est pas interprété par la même manière parce que le but diffère. L’une est vue comme pénible car ne rapporte pas assez au chercheur (en terme de visibilité, réseautage, découverte), l’autre est comme incorporée, acceptée comme un travail normal.
Enfin je me demande si la dimension « réseau social » renforce la perception du chercheur qu’il s’agit d’un travail plus personnel. Comme je ne demanderais pas à une personne tierce de remplir mon compte Facebook ou Twitter (sauf les professionnels qui ont un service de com) par ce que cela situe dans la sphère plus personnelle que professionnelle. Par conséquent le travail de donnée sur ces réseaux est d’emblée plus acceptée parce qu’il s’agit d’un travail davantage personnel alors que le dépôt sur une archive de type HAL est perçu davantage comme une tache à dimension plus professionnelle que personnelle. Cette différence de représentation du travail de donnée reliée à un but visé serait une explication de cette différence de subjectivité. C’ est une question … rien de certain…